 Follow us on twitter
Follow us on twitter The Importance of Interactive Data Analysis for Data-Driven Discovery
03 Apr 2017 By Rafa IrizarryData analysis workflows and recipes are commonly used in science. They are actually indispensable since reinventing the wheel for each project would result in a colossal waste of time. On the other hand, mindlessly applying a workflow can result in totally wrong conclusions if the required assumptions don’t hold. This is why successful data analysts rely heavily on interactive data analysis (IDA). I write today because I am somewhat concerned that the importance of IDA is not fully appreciated by many of the policy makers and thought leaders that will influence how we access and work with data in the future.
I start by constructing a very simple example to illustrate the importance of IDA. Suppose that as part of a demographic study you are asked to summarize male heights across several counties. Since sample sizes are large and heights are known to be well approximated by a normal distribution you feel comfortable using a true and tested recipe: report the average and standard deviation as a summary. You are surprised to find a county with average heights of 6.1 feet with a standard deviation (SD) of 7.8 feet. Do you start writing a paper and a press release to describe this very interesting finding? Here, interactive data analysis saves us from naively reporting this. First, we note that the standard deviation is impossibly big if data is in fact normally distributed: more than 15% of heights would be negative. Given this nonsensical result, the next obvious step for an experienced data analyst is to explore the data, say with a boxplot (see below). This immediately reveals a problem, it appears one value was reported in centimeters: 180 centimeters not feet. After fixing this, the summary changes to an average height of 5.75 and with a 3 inch SD.
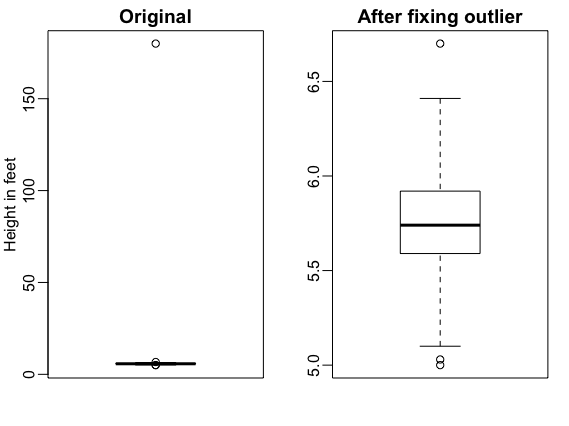
Years of data analysis experience will show you that examples like this are common. Unfortunately, as data and analyses get more complex, workflow failures are harder to detect and often go unnoticed. An important principle many of us teach our trainees is to carefully check for hidden problems when data analysis leads you to unexpected results, especialy when the unexpected results holding up benefits us professionally, for example by leading to a publication.
Interactive data analysis is also indispensable for the development of new methodology. For example, in my field of research, exploring the data has led to the discovery of the need for new methods and motivated new approaches that handle specific cases that existing workflows can’t handle.
So why I am concerned? As public datasets become larger and more numerous, many funding agencies, policy makers and industry leaders are advocating for using cloud computing to bring computing to the data. If done correctly, this would provide a great improvement over the current redundant and unsystematic approach of everybody downloading data and working with it locally. However, after looking into the details of some of these plans, I have become a bit concerned that perhaps the importance of IDA is not fully appreciated by decision makers.
As an example consider the NIH efforts to promote data-driven discovery that center around plans for the Data Commons. The linked page describes an ecosystem with four components one of which is “Software”. According to the description, the software component of The Commons should provide “[a]ccess to and deployment of scientific analysis tools and pipeline workflows”. There is no mention of a strategy that will grant access to the raw data. Without this, carefully checking the workflow output and developing the analysis tools and pipeline workflows of the future will be difficult.
I note that data analysis workflows are very popular in fields in which data analysis is indispensible, as is the case in biomedical research, my focus area. In this field, data generators, which typically lead the scientific enterprise, are not always trained data analysts. But the literature is overflowing with proposed workflows. You can gauge the popularity of these by the vast number published in the nature journals as demonstrated by this google search:

In a field in which data generators are not data analysis experts, the workflow has the added allure that it removes the need to think deeply about data analysis and instead shifts the responsibility to pre-approved software. Note that these workflows are not always described with the mathematical language or computer coded needed to truly understand it but rather with a series of PowerPoint shapes. The gist of the typical data analysis workflow can be simplified into the following:
This simplification of the data analysis process makes it particularly worrisome that the intricacies of IDA are not fully appreciated.
As mentioned above, data analysis workflows are a necessary component of the scientific enterprise. Without them the process would slow down to a halt. However, workflows should only be implemented once consensus is reached regarding its optimality. And even then, IDA is needed to assure that the process is performing as expected. The career of many of my colleagues has been dedicated mostly to the development of such analysis tools. We have learned that rushing to implement workflows before they are mature enough can have widespread negative consequences. And, at least in my experience, developing rigorous tools is impossible without interactive data analysis. So I hope that this post helps make a case for the importance of interactive data analysis and that it continues to be a part of the scientific enterprise.