 Follow us on twitter
Follow us on twitter The relativity of raw data
20 Jul 2016 By Jeff Leek“Raw data” is one of those terms that everyone in statistics and data science uses but no one defines. For example, we all agree that we should be able to recreate results in scientific papers from the raw data and the code for that paper.
But what do we mean when we say raw data?
When working with collaborators or students I often find myself saying - could you just give me the raw data so I can do the normalization or processing myself. To give a concrete example, I work in the analysis of data from high-throughput genomic sequencing experiments.
These experiments produce data by breaking up genomic molecules into short fragements of DNA - then reading off parts of those fragments to generate “reads” - usually 100 to 200 letters long per read. But the reads are just puzzle pieces that need to be fit back together and then quantified to produce measurements on DNA variation or gene expression abundances.
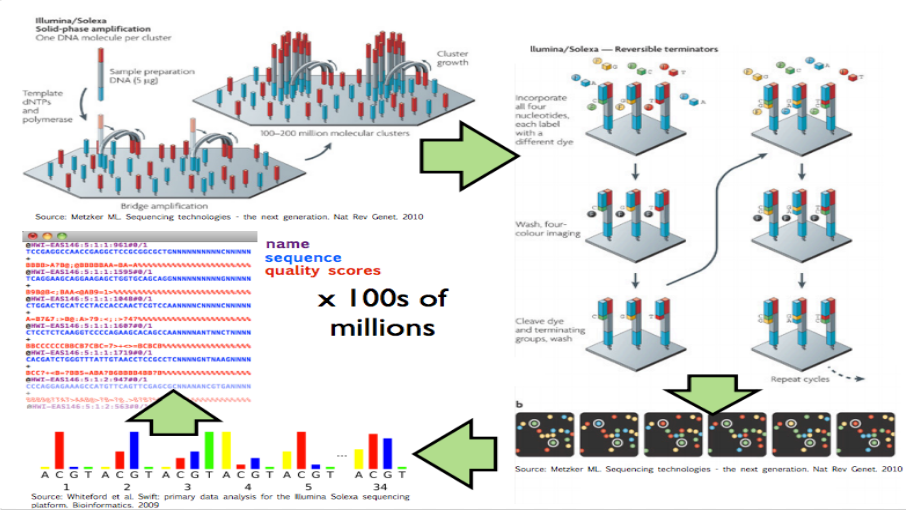
Image from Hector Corrata Bravo’s lecture notes
When I say “raw data” when talking to a collaborator I mean the reads that are reported from the sequencing machine. To me that is the rawest form of the data I will look at. But to generate those reads the sequencing machine first (1) created a set of images for each letter in the sequence of reads, (2) measured the color at the spots on that image to get the quantitative measurement of which letter, and (3) calculated which letter was there with a confidence measure. The raw data I ask for only includes the confidence measure and the sequence of letters itself, but ignores the images and the colors extracted from them (steps 1 and 2).
So to me the “raw data” is the files of reads. But to the people who produce the machine for sequencing the raw data may be the images or the color data. To my collaborator the raw data may be the quantitative measurements I calculate from the reads. When thinking about this I realized an important characteristics of raw data.
Raw data is relative to your reference frame.
In other words the raw data is raw to you if you have done no processing, manipulation, coding, or analysis of the data. In other words, the file you received from the person before you is untouched. But it may not be the rawest version of the data. The person who gave you the raw data may have done some computations. They have a different “raw data set”.
The implication for reproducibility and replicability is that we need a “chain of custody” just like with evidence collected by the police. As long as each person keeps a copy and record of the “raw data” to them you can trace the provencance of the data back to the original source.