01 Oct 2016
Hilary and Roger invite Walt Hickey of FiveThirtyEight.com on to the show to talk about polling, movies, and data analysis reproducibility (of course).
If you have questions you’d like us to answer, you can send them to
nssdeviations @ gmail.com or tweet us at @NSSDeviations.
Subscribe to the podcast on iTunes or Google Play.
Please leave us a review on iTunes.
Support us through our Patreon page.
Get the Not So Standard Deviations book.
Show Notes:
Download the audio for this episode.
Listen here:
29 Sep 2016
Over the last few months there has been a lot of vitriol around statistical ideas. First there were data parasites and then there were methodological terrorists. These epithets came from established scientists who have relatively little statistical training. There was the predictable backlash to these folks from their counterparties, typically statisticians or statistically trained folks who care about open source.
I’m a statistician who cares about open source but I also frequently collaborate with scientists from different fields. It makes me sad and frustrated that statistics - which I’m so excited about and have spent my entire professional career working on - is something that is causing so much frustration, anxiety, and anger.
I have been thinking a lot about the cause of this anger and division in the sciences. As a person who interacts with both groups pretty regularly I think that the reasons are some combination of the following.
- Data is now everywhere, so every single publication involves some level of statistical modeling and analysis. It can’t be escaped.
- The deluge of scientific papers means that only big claims get your work noticed, get you into fancy journals, and get you attention.
- Most senior scientists, the ones leading and designing studies, have little or no training in statistics. There is a structural reason for this: data was sparse when they were trained and there wasn’t any reason for them to learn statistics. So statistics and data science wasn’t (and still often isn’t) integrated into medical and scientific curricula.
- There is an imbalance of power in the scientific process between statisticians/computational scientists and scientific investigators or clinicians. The clinicians/scientific investigators are “in charge” and the statisticians are often relegated to a secondary role. Statisticians with some control over their environment (think senior tenured professors of (bio)statistics) can avoid these imbalances and look for collaborators who respect statistical thinking, but not everyone can. There are a large number of lonely bioinformaticians out there.
- Statisticians and computational scientists are also frustrated because their is often no outlet for them to respond to these papers in the formal scientific literature - those outlets are controlled by scientists and rarely have statisticians in positions of influence within the journals.
Since statistics is everywhere (1) and only flashy claims get you into journals (2) and the people leading studies don’t understand statistics very well (3), you get many publications where the paper makes a big claim based on shakey statistics but it gets through. This then frustrates the statisticians because they have little control over the process (4) and can’t get their concerns into the published literature (5).
This used to just result in lots of statisticians and computational scientists complaining behind closed doors. The internet changed all that, everyone is an internet scientist now. So the statisticians and statistically savvy take to blogs, f1000research, and other outlets to get their point across.
Sometimes to get attention, statisticians start to have the same problem as scientists; they need their complaints to get attention to have any effect. So they go over the top. They accuse people of fraud, or being statistically dumb, or nefarious, or intentionally doing things with data, or cast a wide net and try to implicate a large number of scientists in poor statistics. The ironic thing is that these things are the same thing that the scientists are doing to get attention that frustrated the statisticians in the first place.
Just to be 100% clear here I am also guilty of this. I have definitely fallen into the hype trap - talking about the “replicability crisis”. I also made the mistake earlier in my blogging career of trashing the statistics of a paper that frustrated me. I am embarrassed I did that now, it wasn’t constructive and the author ended up being very responsive. I think if I had just emailed that person they would have resolved their problem.
I just recently had an experience where a very prominent paper hadn’t made their data public and I was having trouble getting the data. I thought about writing a blog post to get attention, but at the end of the day just did the work of emailing the authors, explaining myself over and over and finally getting the data from them. The result is the same (I have the data) but it cost me time and frustration. So I understand when people don’t want to deal with that.
The problem is that scientists see the attention the statisticians are calling down on them - primarily negative and often over-hyped. Then they get upset and call the statisticians/open scientists names, or push back on entirely sensible policies because they are worried about being humiliated or discredited. While I don’t agree with that response, I also understand the feeling of “being under attack”. I’ve had that happen to me too and it doesn’t feel good.
So where do we go from here? How do we end statistical vitriol and make statistics a positive force? Here is my six part plan:
- We should create continuining education for senior scientists and physicians in statistical and open data thinking so people who never got that training can understand the unique requirements of a data rich scientific world.
- We should encourage journals and funders to incorporate statisticians and computational scientists at the highest levels of influence so that they can drive policy that makes sense in this new data driven time.
- We should recognize that scientists and data generators have a lot more on the line when they produce a result or a scientific data set. We should give them appropriate credit for doing that even if they don’t get the analysis exactly right.
- We should de-escalate the consequences of statistical mistakes. Right now the consequences are: retractions that hurt careers, blog posts that are aggressive and often too personal, and humiliation by the community. We should make it easy to acknowledge these errors without ruining careers. This will be hard - scientists careers often depend on the results they get (recall 2 above). So we need a way to pump up/give credit to/acknowledge scientists who are willing to sacrifice that to get the stats right.
- We need to stop treating retractions/statistical errors/mistakes like a sport where there are winners and losers. Statistical criticism should be easy, allowable, publishable and not angry or personal.
- Any paper where statistical analysis is part of the paper must have both a statistically trained author or a statistically trained reviewer or both. I wouldn’t believe a paper on genomics that was performed entirely by statisticians with no biology training any more than I believe a paper with statistics in it performed entirely by physicians with no statistical training.
I think scientists forget that statisticians feel un-empowered in the scientific process and statisticians forget that a lot is riding on any given study for a scientist. So being a little more sympathetic to the pressures we all face would go a long way to resolving statistical vitriol.
I’d be eager to hear other ideas too. It makes me sad that statistics has become so political on both sides.
28 Sep 2016
Palantir, the secretive data science/consulting/software company, continues to be a mystery to most people, but recent reports have not been great. Reuters reports that the U.S. Department of Labor is suing it for employment discrimination:
The lawsuit alleges Palantir routinely eliminated Asian applicants in the resume screening and telephone interview phases, even when they were as qualified as white applicants.
Interestingly, the report indicates a statistical argument:
In one example cited by the Labor Department, Palantir reviewed a pool of more than 130 qualified applicants for the role of engineering intern. About 73 percent of applicants were Asian. The lawsuit, which covers Palantir’s conduct between January 2010 and the present, said the company hired 17 non-Asian applicants and four Asians. “The likelihood that this result occurred according to chance is approximately one in a billion,” said the lawsuit, which was filed with the department’s Office of Administrative Law Judges.
Update: Thanks to David Robinson for point out that (a) I read the numbers incorrectly and (b) I should have used the hypergeometric distribution to account for the sampling without replacement. The paragraph below is corrected accordingly.
Note the use of the phrase “qualified applicants” in reference to the
- Presumably, there was a screening process that removed
“unqualified applicants” and that led us to 130. Of the 130, 73% were
Asian. Presumably, there was a follow up selection process (interview,
exam) that led to 4 Asians being hired out of 21 (about 19%). Clearly
there’s a difference between 19% and 73% but the reasons may not be
nefarious. If you assume the number of Asians hired is proportional to
the number in the qualified pool, then the p-value for the observed
data is about 10^-8, which is not quite “1 in a billion” as the
report claims but it’s indeed small. But my guess is the Labor
Department has more than this test of binomial proportions in terms of
evidence if they were to go through with a suit.
Alfred Lee from The Information reports that a mutual fund run by Valic sold their shares of Palantir for below the recent valuation:
The Valic fund sold its stake at $4.50 per share, filings show, down from the $11.38 per share at which the company raised money in December. The value of the stake at the sale price was $621,000. Despite the price drop, Valic made money on the deal, as it had acquired stock in preferred fundraisings in 2012 and 2013 at between $3.06 and $3.51 per share.
The valuation suggested in the article by the recent sale is $8 billion. In my previous post on Palantir, I noted that while other large-scale consulting companies certainly make a lot of money, none have the sky-high valuation that Palantir commands. However, a more “down-to-Earth” valuation of $8 billion might be more or less in line with these other companies. It may be bad news for Palantir, but should the company ever have an IPO, it would be good for the public for market participants to realize the intrinsic value of the company.
27 Sep 2016
Democratic elections permit us to vote for whomever we perceive has
the highest expectation to do better with the issues we care about. Let’s
simplify and assume we can quantify how satisfied we are with an
elected official’s performance. Denote this quantity with X. Because
when we cast our vote we still don’t know for sure how the candidate
will perform, we base our decision on what we expect, denoted here with
E(X). Thus we try to maximize E(X). However, both political theory
and data tell us that in US presidential elections only two parties
have a non-negligible probability of winning. This implies that
E(X) is 0 for some candidates no matter how large X could
potentially be. So what we are really doing is deciding if E(X-Y) is
positive or negative with X representing one candidate and Y the
other.
In past elections some progressives have argued that the difference
between candidates is negligible and have therefore supported the Green Party
ticket. The 2000 election is a notable example. The
2000 election
was won by George W. Bush by just five electoral votes. In Florida,
which had 25 electoral votes, Bush beat Al
Gore by just 537 votes. Green Party candidate Ralph
Nader obtained 97,488 votes. Many progressive voters were OK with this
outcome because they perceived E(X-Y) to be practically 0.
In contrast, in 2016, I suspect few progressives think that
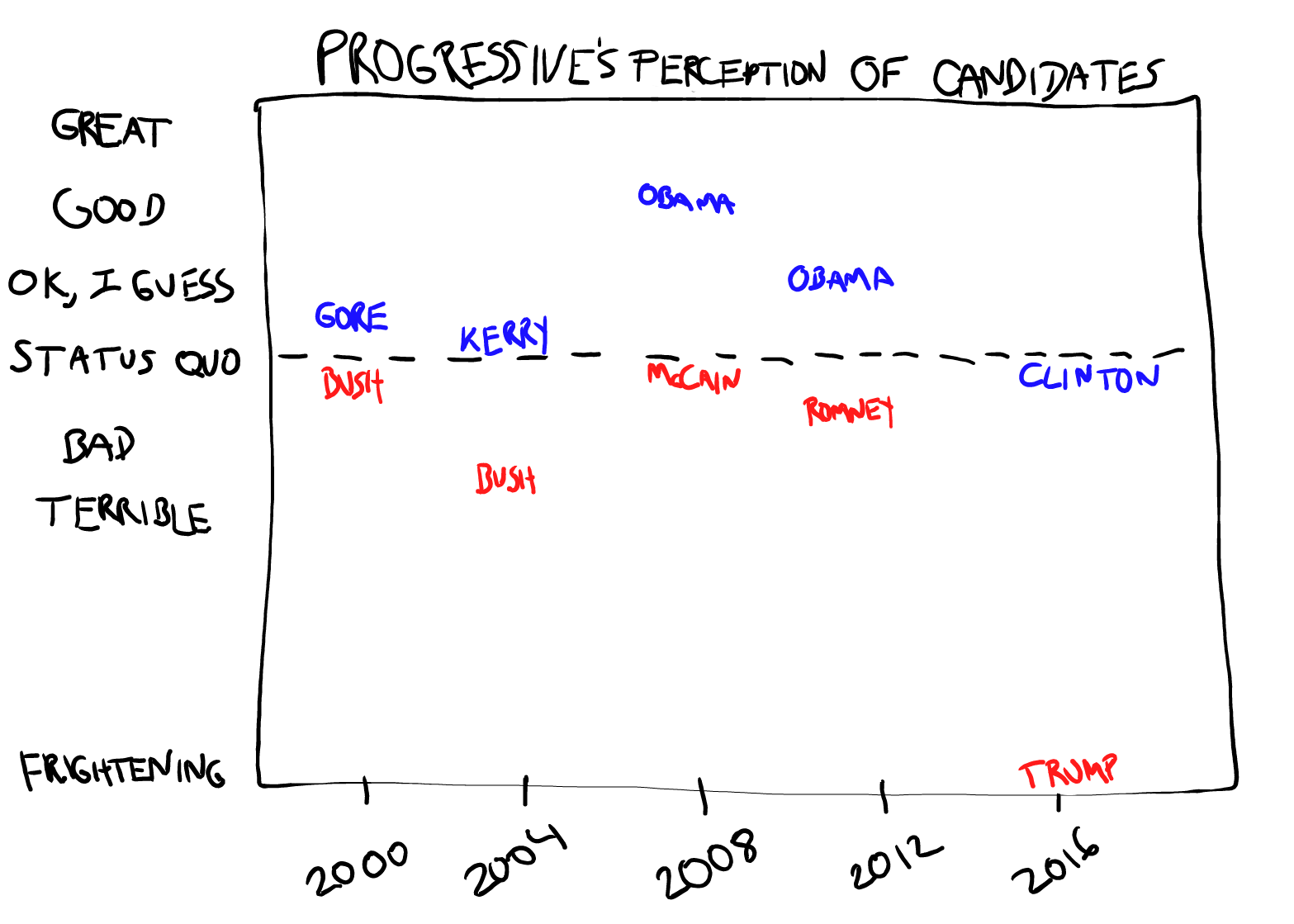
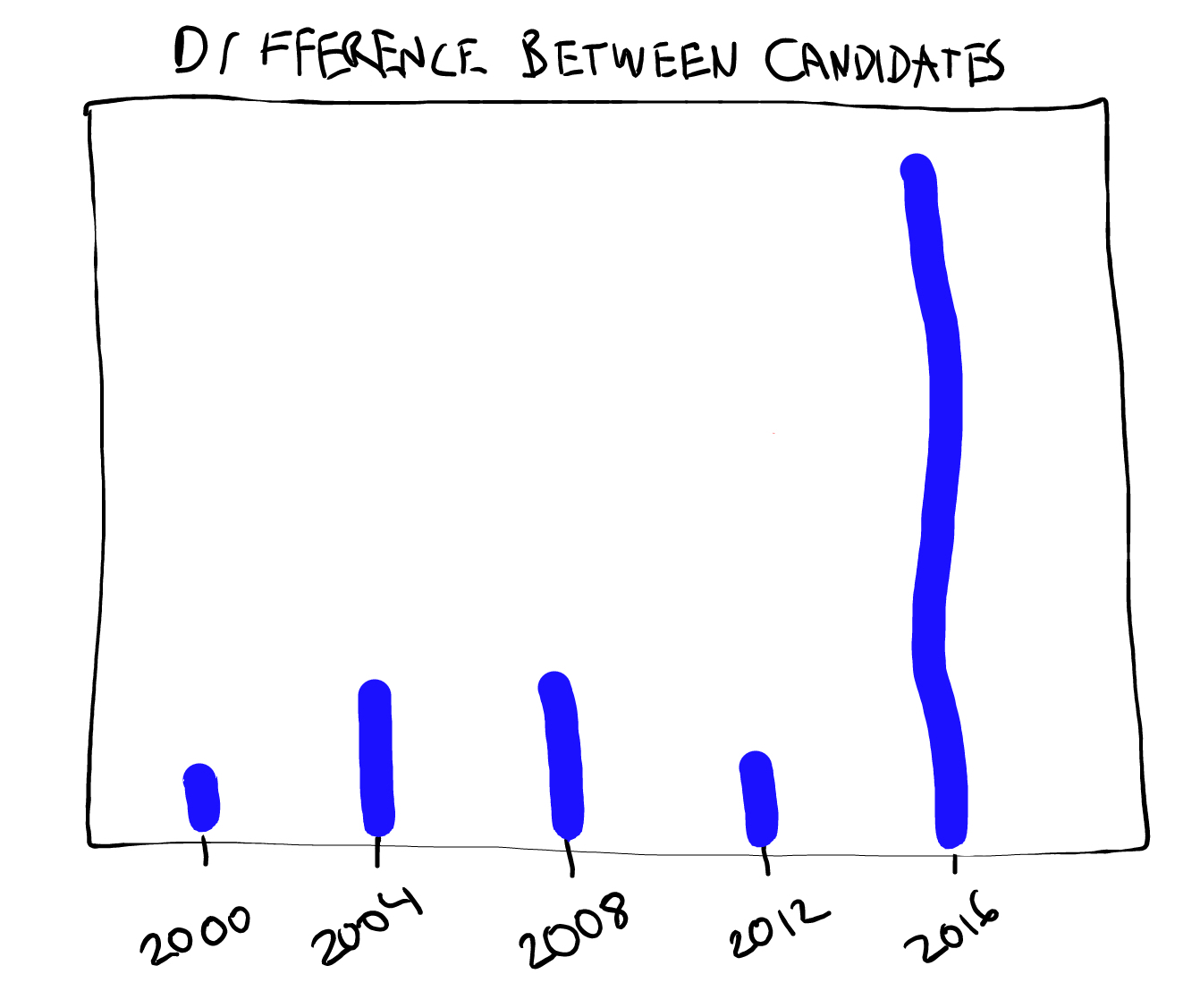
E(X-Y) is anywhere near 0. In the figures below I attempt to
quantify the progressive’s pre-election perception of consequences for
the last five contests. The first
figure shows E(X) and E(Y) and the second shows E(X-Y). Note
despite E(X) being the lowest in the last past five elections,
E(X-Y) is by far the largest. So if these figures accurately depict
your perception and you think
like a statistician, it becomes clear that this is not the election to
vote third party.
26 Sep 2016
From the Wall Street Journal:
Several weeks ago, Facebook disclosed in a post on its “Advertiser Help Center” that its metric for the average time users spent watching videos was artificially inflated because it was only factoring in video views of more than three seconds. The company said it was introducing a new metric to fix the problem.
A classic case of left censoring (in this case, by “accident”).
Also this:
Ad buying agency Publicis Media was told by Facebook that the earlier counting method likely overestimated average time spent watching videos by between 60% and 80%, according to a late August letter Publicis Media sent to clients that was reviewed by The Wall Street Journal.
What does this information tell us about the actual time spent watching Facebook videos?
 Follow us on twitter
Follow us on twitter