26 Jan 2017
Are you interested in building data apps to help save the world, start the next big business, or just to see if you can? We are running a data app prototyping class for people interested in creating these apps.
This will be a special topics class at JHU and is open to any undergrad student, grad student, postdoc, or faculty member at the university. We are also seeing if we can make the class available to people outside of JHU so even if you aren’t at JHU but are interested you should let us know below.
One of the principles of our approach is that anyone can prototype an app. Our class starts with some tutorials on Shiny and R. While we have no formal pre-reqs for the class you will have much more fun if you have the background equivalent to our Coursera classes:
If you don’t have that background you can take the classes online starting now to get up to speed! To see some examples of apps we will be building check out our gallery.
We will mostly be able to support development with R and Shiny but would be pumped to accept people with other kinds of development background - we just might not be able to give a lot of technical assistance.
As part of the course we are also working with JHU’s Fast Forward program to streamline and ease the process of starting a company around the app you build for the class. So if you have entrepreneurial ambitions, this is the class for you!
We are in the process of setting up the course times, locations, and enrollment cap. The class will run from March to May (exact dates TBD). To sign up for announcements about the class please fill out your information here.
23 Jan 2017
Over the past year, there have been a number of recurring topics in my global news feed that have a shared theme to them. Some examples of these topics are:
- Fake news: Before and after the election in 2016, Facebook (or Facebook’s Trending News algorithm) was accused of promoting news stories that turned out to be completely false, promoted by dubious news sources in FYROM and elsewhere.
- Theranos: This diagnostic testing company promised to revolutionize the blood testing business and prevent disease for all by making blood testing simple and painless. This way people would not be afraid to get blood tests and would do them more often, presumably catching diseases while they were in the very early stages. Theranos lobbied to allow patients order their own blood tests so that they wouldn’t need a doctor’s order.
- Homeopathy: This a so-called alternative medical system developed in the late 18th century based on notions such as “like cures like” and “law of minimum dose.
- Online education: New companies like Coursera and Udacity promised to revolutionize education by making it accessible to a broader audience than conventional universities were able.
What exactly do these things have in common?
First, consumers love them. Fake news played to people’s biases by confirming to them, from a seemingly trustworthy source, what they always “knew to be true”. The fact that the stories weren’t actually true was irrelevant given that users enjoyed the experience of seeing what they agreed with. Perhaps the best explanation of the entire Facebook fake news issue was from Kim-Mai Cutler:
Theranos promised to revolutionize blood testing and change the user experience behind the whole industry. Indeed the company had some fans (particularly amongst its investor base). However, after investigations by the Center for Medicare and Medicaid Services, the FDA, and an independent laboratory, it was found that Theranos’s blood testing machine was wildly inconsistent and variable, leading to Theranos ultimately retracting all of its blood test results and cutting half its workforce.
Homeopathy is not company specific, but is touted by many as an “alternative” treatment for many diseases, with many claiming that it “works for them”. However, the NIH states quite clearly on its web site that “There is little evidence to support homeopathy as an effective treatment for any specific condition.”
Finally, companies like Coursera and Udacity in the education space have indeed produced products that people like, but in some instances have hit bumps in the road. Udacity conducted a brief experiment/program with San Jose State University that failed due to the large differences between the population that took online courses and the one that took them in person. Coursera has massive offerings from major universities (including my own) but has run into continuing challenges with drop out and questions over whether the courses offered are suitable for job placement.
User Experience and Value
In each of these four examples there is a consumer product that people love, often because they provide a great user experience. Take the fake news example–people love to read headlines from “trusted” news sources that agree with what they believe. With Theranos, people love to take a blood test that is not painful (maybe “love” is the wrong word here). With many consumer products companies, it is the user experience that defines the value of a product. Often when describing the user experience, you are simultaneously describing the value of the product.
Take for example Uber. With Uber, you open an app on your phone, click a button to order a car, watch the car approach you on your phone with an estimate of how long you will be waiting, get in the car and go to your destination, and get out without having to deal with paying. If someone were to ask me “What’s the value of Uber?” I would probably just repeat the description in the previous sentence. Isn’t it obvious that it’s better than the usual taxi experience? The same could be said for many companies that have recently come up: Airbnb, Amazon, Apple, Google. With many of the products from these companies, the description of the user experience is a description of its value.
Disruption Through User Experience
In the example of Uber (and Airbnb, and Amazon, etc.) you could depict the relationship between the product, the user experience, and the value as such:
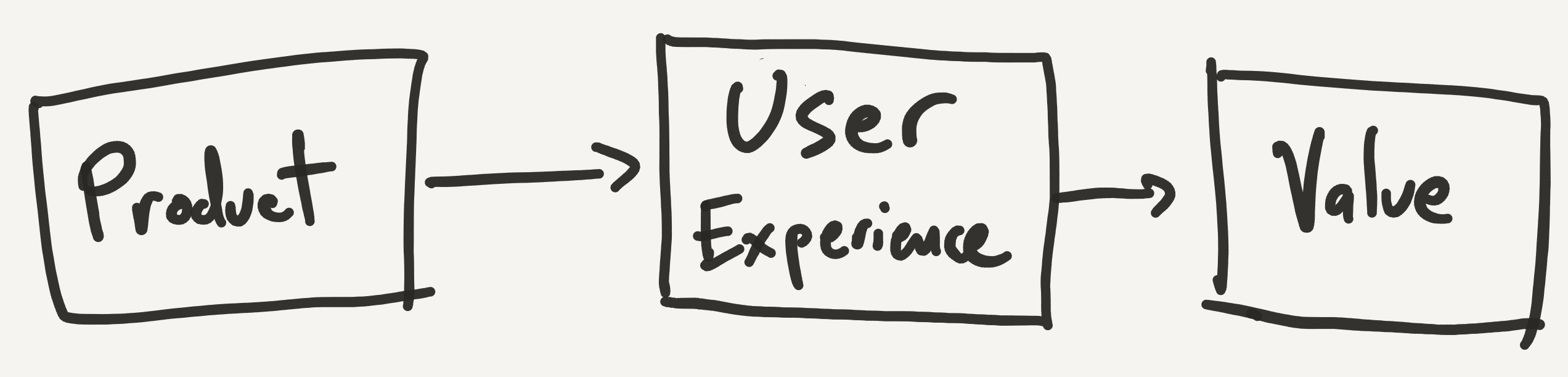
Any changes that you can make to the product to improve the user experience will then improve the value that the product offers. Another way to say it is that the user experience serves as a surrogate outcome for the value. We can influence the UX and know that we are improving value. Furthermore, any measurements that we take on the UX (surveys, focus groups, app data) will serve as direct observations on the value provided to customers.
New companies in these kinds of consumer product spaces can disrupt the incumbents by providing a much better user experience. When incumbents have gotten fat and lazy, there is often a sizable segment of the customer base that feels underserved. That’s when new companies can swoop in to specifically serve that segment, often with a “worse” product overall (as in fewer features) and usually much cheaper. The Internet has made the “swooping in” much easier by dramatically reducing transaction and distribution costs. Once the new company has a foothold, they can gradually work their way up the ladder of customer segments to take over the market. It’s classic disruption theory a la Clayton Christensen.
When Value Defines the User Experience and Product
There has been much talk of applying the classic disruption model to every space imaginable, but I contend that not all product spaces are the same. In particular, the four examples I described in the beginning of this post cover some of those different areas:
- Medicine (Theranos, homeopathy)
- News (Facebook/fake news)
- Education (Coursera/Udacity)
One thing you’ll notice about these areas, particularly with medicine and education, is that they are all heavily regulated. The reason is because we as a community have decided that there is a minimum level of value that is required to be provided by entities in this space. That is, the value that a product offers is defined first, before the product can come to market. Therefore, the value of the product actually constrains the space of products that can be produced. We can depict this relationship as such:
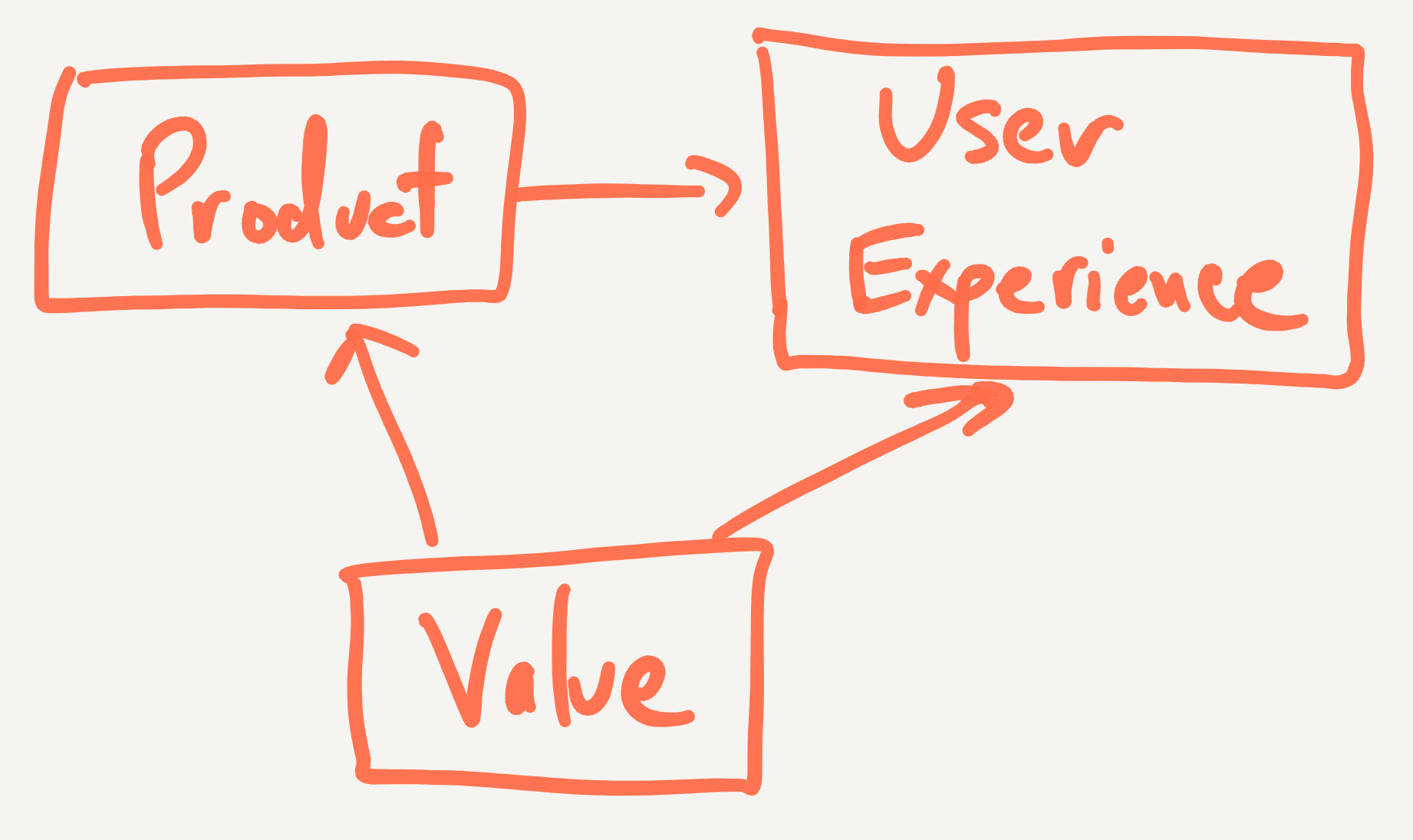
In classic regression modeling language, the value of a product must be “adjusted for” before examining the relationship between the product and the user experience. Naturally, as in any regression problem, when you adjust for a variable that is related to the product and the user experience, you reduce the overall variation in the product.
In situations where the value defines the product and the user experience, there is much less room to maneuver for new entrants in the market. The reason is because they, like everyone else, are constrained by the value that is agreed upon by the community, usually in the form of regulations.
When Theranos comes in and claims that it’s going to dramatically improve the user experience of blood testing, that’s great, but they must be constrained by the value that society demands, which is a certain precision and accuracy in its testing results. Companies in the online education space are welcome to disrupt things by providing a better user experience. Online offerings in fact do this by allowing students to take classes according to their own schedule, wherever they may live in the world. But we still demand that the students learn an agreed-upon set of facts, skills, or lessons.
New companies will often argue that the things that we currently value are outdated or no longer valuable. Their incentive is to change the value required so that there is more room for new companies to enter the space. This is a good thing, but it’s important to realize that this cannot happen solely through changes in the product. Innovative features of a product may help us to understand that we should be valuing different things, but ultimately the change in what we preceive as value occurs independently of any given product.
When I see new companies enter the education, medicine, or news areas, I always hesitate a bit because I want some assurance that they will still provide the value that we have come to expect. In addition, with these particular areas, there is a genuine sense that failing to deliver on what we value could cause serious harm to individuals. However, I think the discussion that is provoked by new companies entering the space is always welcome because we need to constantly re-evaluate what we value and whether it matches the needs of our time.
20 Jan 2017
Editor’s note: This is the second chapter of a book I’m working on called Demystifying Artificial Intelligence. The goal of the book is to demystify what modern AI is and does for a general audience. So something to smooth the transition between AI fiction and highly mathematical descriptions of deep learning. I’m developing the book over time - so if you buy the book on Leanpub know that there are only two chapters in there so far, but I’ll be adding more over the next few weeks and you get free updates. The cover of the book was inspired by this amazing tweet by Twitter user @notajf. Feedback is welcome and encouraged!
“I am so clever that sometimes I don’t understand a single word of
what I am saying.” Oscar Wilde
As we have described it artificial intelligence applications consist of
three things:
- A large collection of data examples
- An algorithm for learning a model from that training set.
- An interface with the world.
In the following chapters we will go into each of these components in
much more detail, but lets start with a a couple of very simple examples
to make sure that the components of an AI are clear. We will start with
a completely artificial example and then move to more complicated
examples.
Building an album
Lets start with a very simple hypothetical example that can be
understood even if you don’t have a technical background. We can also
use this example to define some of the terms we will be discussing later
in the book.
In our simple example the goal is to make an album of photos for a
friend. For example, suppose I want to take the photos in my photobook
and find all the ones that include pictures of myself and my son Dex for
his grandmother.
If you are anything like the author of this book, then you probably have
a very large number of pictures of your family on your phone. So the
first step in making the photo alubm would be to stort through all of my
pictures and pick out the ones that should be part of the album.
This is a typical example of the type of thing we might want to train a
computer to do in an artificial intelligence application. Each of the
components of an AI application is there:
- The data: all of the pictures on the author’s phone (a big
training set!)
- The algorithm: finding pictures of me and my son Dex
- The interface: the album to give to Dex’s grandmother.
One way to solve this problem is for me to sort through the pictures one
by one and decide whether they should be in the album or not, then
assemble them together, and then put them into the album. If I did it
like this then I myself would be the AI! That wouldn’t be very
artificial though…imagine we instead wanted to teach a computer to
make this album..
But what does it mean to “teach” a computer to do something?
The terms “machine learning” and “artificial intelligence” invoke the
idea of teaching computers in the same way that we teach children. This
was a deliberate choice to make the analogy - both because in some ways
it is appropriate and because it is useful for explaining complicated
concepts to people with limited backgrounds. To teach a child to find
pictures of the author and his son, you would show her lots of examples
of that type of picture and maybe some examples of the author with other
kids who were not his son. You’d repeat to the child that the pictures
of the author and his son were the kinds you wanted and the others
weren’t. Eventually she would retain that information and if you gave
her a new picture she could tell you whether it was the right kind or
not.
To teach a machine to perform the same kind of recognition you go
through a similar process. You “show” the machine many pictures labeled
as either the ones you want or not. You repeat this process until the
machine “retains” the information and can correctly label a new photo.
Getting the machine to “retain” this information is a matter of getting
the machine to create a set of step by step instructions it can apply to
go from the image to the label that you want.
The data
The images are what people in the fields of artificial intelligence and
machine learning call “raw data” (Leek, n.d.). The categories of
pictures (a picture of the author and his son or a picture of something
else) are called the “labels” or “outcomes”. If the computer gets to
see the labels when it is learning then it is called “supervised
learning” (Wikipedia contributors 2016) and when the computer doesn’t
get to see the labels it is called “unsupervised learning” (Wikipedia
contributors 2017a).
Going back to our analogy with the child, supervised learning would be
teaching the child to recognize pictures of the author and his son
together. Unsupervised learning would be giving the child a pile of
pictures and asking them to sort them into groups. They might sort them
by color or subject or location - not necessarily into categories that
you care about. But probably one of the categories they would make would
be pictures of people - so she would have found some potentially useful
information even if it wasn’t exactly what you wanted. One whole field
of artificial intelligence is figuring out how to use the information
learned in this “unsupervised” setting and using it for supervised tasks
- this is sometimes called “transfer learning” (Raina et al. 2007) by
people in the field since you are transferring information from one task
to another.
Returning to the task of “teaching” a computer to retain information
about what kind of pictures you want we run into a problem - computers
don’t know what pictures are! They also don’t know what audio clips,
text files, videos, or any other kind of information is. At least not
directly. They don’t have eyes, ears, and other senses along with a
brain designed to decode the information from these senses.
So what can a computer understand? A good rule of thumb is that a
computer works best with numbers. If you want a computer to sort
pictures into an album for you, the first thing you need to do is to
find a way to turn all of the information you want to “show” the
computer into numbers. In the case of sorting pictures into albums - a
supervised learning problem - we need to turn the labels and the images
into numbers the computer can use.
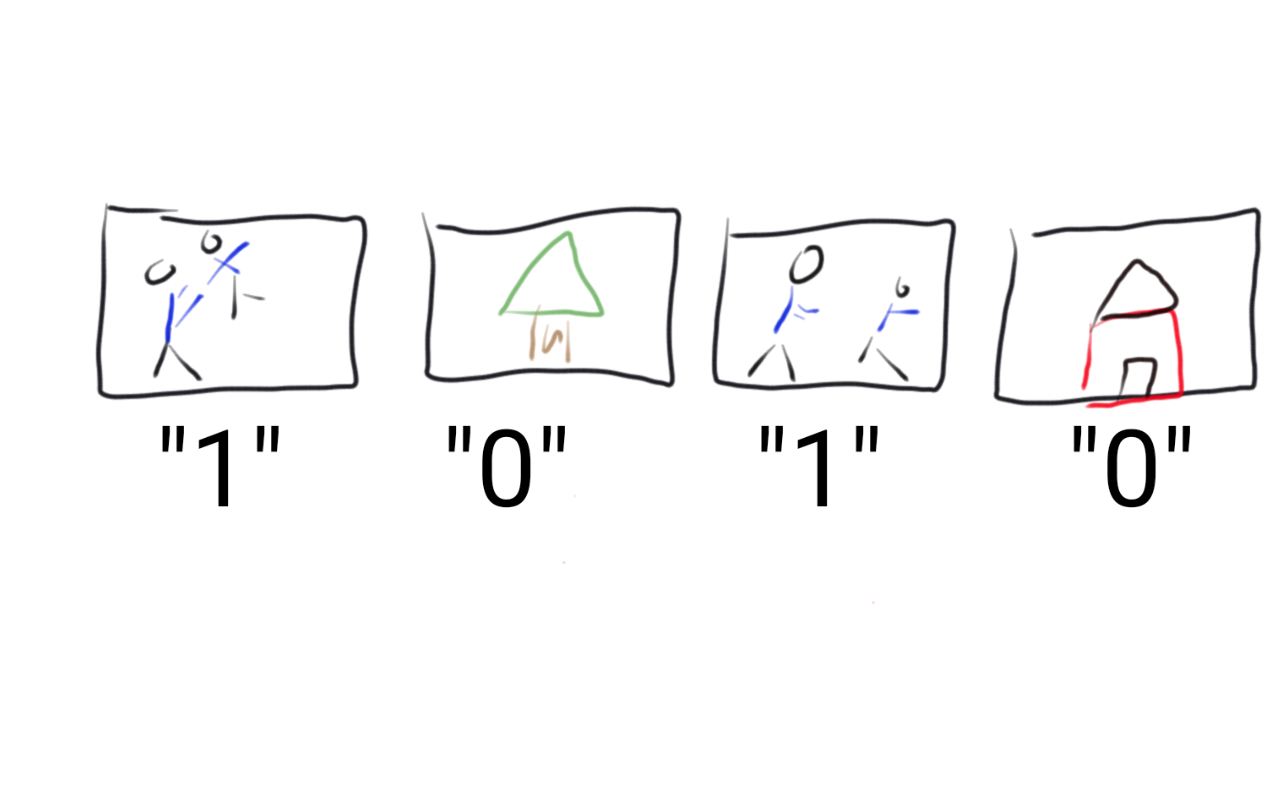
One way to do that would be for you to do it for the computer. You could
take every picture on your phone and label it with a 1 if it was a
picture of the author and his son and a 0 if not. Then you would have a
set of 1’s and 0’s corresponding to all of the pictures. This takes some
thing the computer can’t understand (the picture) and turns it into
something the computer can understand (the label).
This process would turn the labels into something a computer could
understand, it still isn’t something we could teach a computer to do.
The computer can’t actually “look” at the image and doesn’t know who the
author or his son are. So we need to figure out a way to turn the images
into numbers for the computer to use to generate those labels directly.
This is a little more complicated but you could still do it for the
computer. Let’s suppose that the author and his son always wear matching
blue shirts when they spend time together. Then you could go through and
look at each image and decide what fraction of the image is blue. So
each picture would get a number ranging from zero to one like 0.30 if
the picture was 30% blue and 0.53 if it was 53% blue.
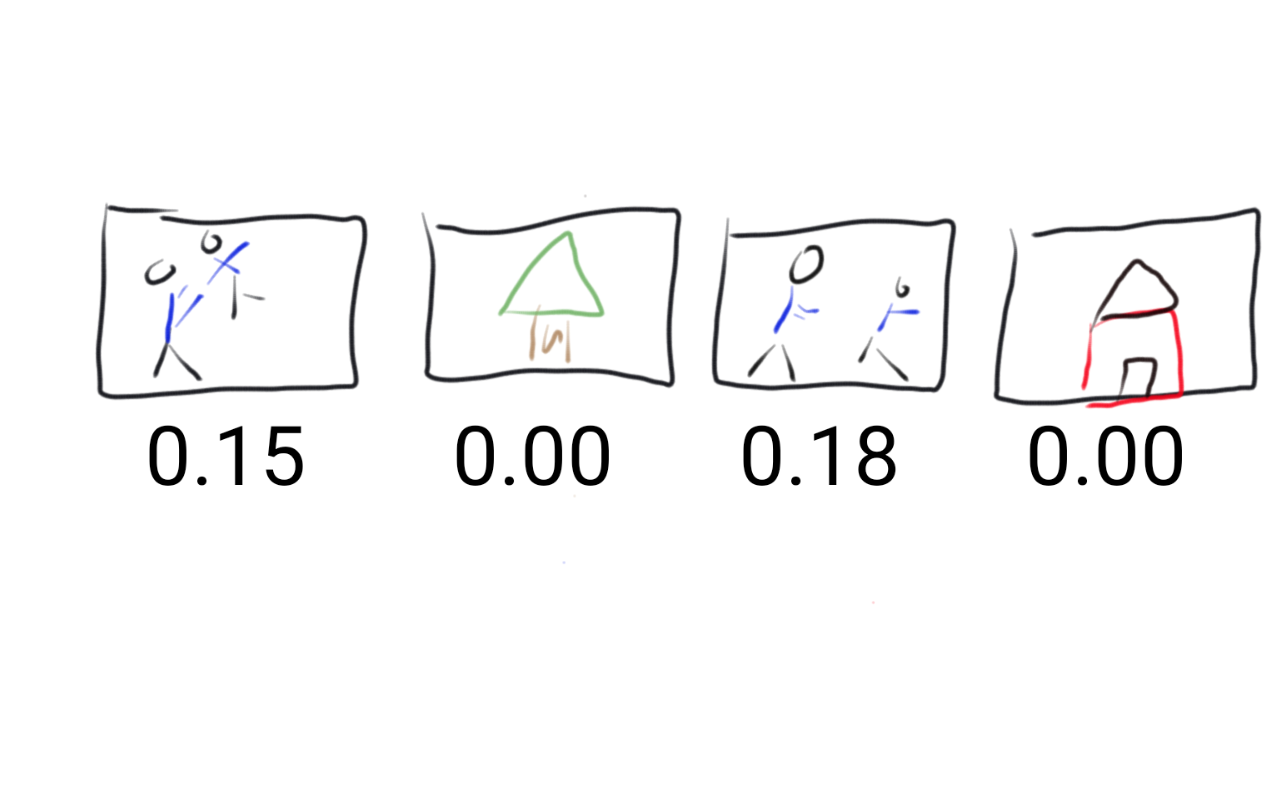
The fraction of the picture that is blue is called a “feature” and the
process of creating that feature is called “feature engineering”
(Wikipedia contributors 2017b). Until very recently feature engineering
of text, audio, or video files was best performed by an expert human. In
later chapters we will discuss how one of the most exciting parts about
AI application is that it is now possible to have computers perform
feature engineering for you.
The algorithm
Now that we have converted the images to numbers and the labels to
numbers, we can talk about how to “teach” a computer to label the
pictures. A good rule of thumb when thinking about algorithms is that a
computer can’t “do” anything without being told very explicitly what to
do. It needs a step by step set of instructions. The instructions should
start with a calculation on the numbers for the image and should end
with a prediction of what label to apply to that image. The image
(converted to numbers) is the “input” and the label (also a number) is
the “output”. You may have heard the phrase:
“Garbage in, garbage out”
What this phrase means is if the inputs (the images) are bad - say they
are all very dark or hard to see. Then the output of the algorithm will
also be bad - the predictions won’t be very good.
A machine learning “algorithm” can be thought of as a set of
instructions with some of the parts left blank - sort of like mad-libs.
One example of a really simple algorithm for sorting pictures into the
album would be:
- Calculate the fraction of blue in the image.
- If the fraction of blue is above X label it 1
- If the fraction of blue is less than X label it 0
- Put all of the images labeled 1 in the album
The machine “learns” by using the examples to fill in the blanks in
the instructions. In the case of our really simple algorithm we need to
figure out what fraction of blue to use (X) for labeling the picture.
To figure out a guess for X we need to decide what we want the
algorithm to do. If we set X to be too low then all of the images will
be labeled with a 1 and put into the album. If we set X to be too high
then all of the images will be labeled 0 and none will appear in the
album. In between there is some grey area - do we care if we
accidentally get some pictures of the ocean or the sky with our
algorithm?
But the number of images in the album isn’t even the thing we really
care about. What we might care about is making sure that the album is
mostly pictures of the author and his son. In the field of AI they
usually turn this statement around - we want to make sure the album has
a very small fraction of pictures that are not of the author and his
son. This fraction - the fraction that are incorrectly placed in the
album is called the “loss”. You can think about it like a game where
the computer loses a point every time it puts the wrong kind of picture
into the album.
Using our loss (how many pictures we incorrectly placed in the album) we
can now use the data we have created (the numbers for the labels and the
images) to fill in the blanks in our mad-lib algorithm (picking the
cutoff on the amount of blue). We have a large number of pictures where
we know what fraction of each picture is blue and whether it is a
picture of the author and his son or not. We can try each possible X
and calculate the fraction of pictures in the album that are incorrectly
placed into the album (the loss) and find the X that produces the
smallest fraction.
Suppose that the value of X that gives the smallest faction of wrong
pictures in the album is 30. Then our “learned” model would be:
- Calculate the fraction of blue in the image
- If the fraction of blue is above 0.1 label it 1
- If the fraction of blue is less than 0.1 label it 0
- Put all of the images labeled 1 in the album
The interface
The last part of an AI application is the interface. In this case, the
interface would be the way that we share the pictures with Dex’s
grandmother. For example we could imagine uploading the pictures to
Shutterfly and having the album delivered
to Dex’s grandmother.
Putting this all together we could imagine an application using our
trained AI. The author uploads his unlabeled photos. The photos are then
passed to the computer program which calculates the fraction of the
image that is blue, then applies a label according to the algorithm we
learned, then takes all the images predicted to be of the author and his
son and sends them off to be a Shutterfly album mailed to the authors’
mother.
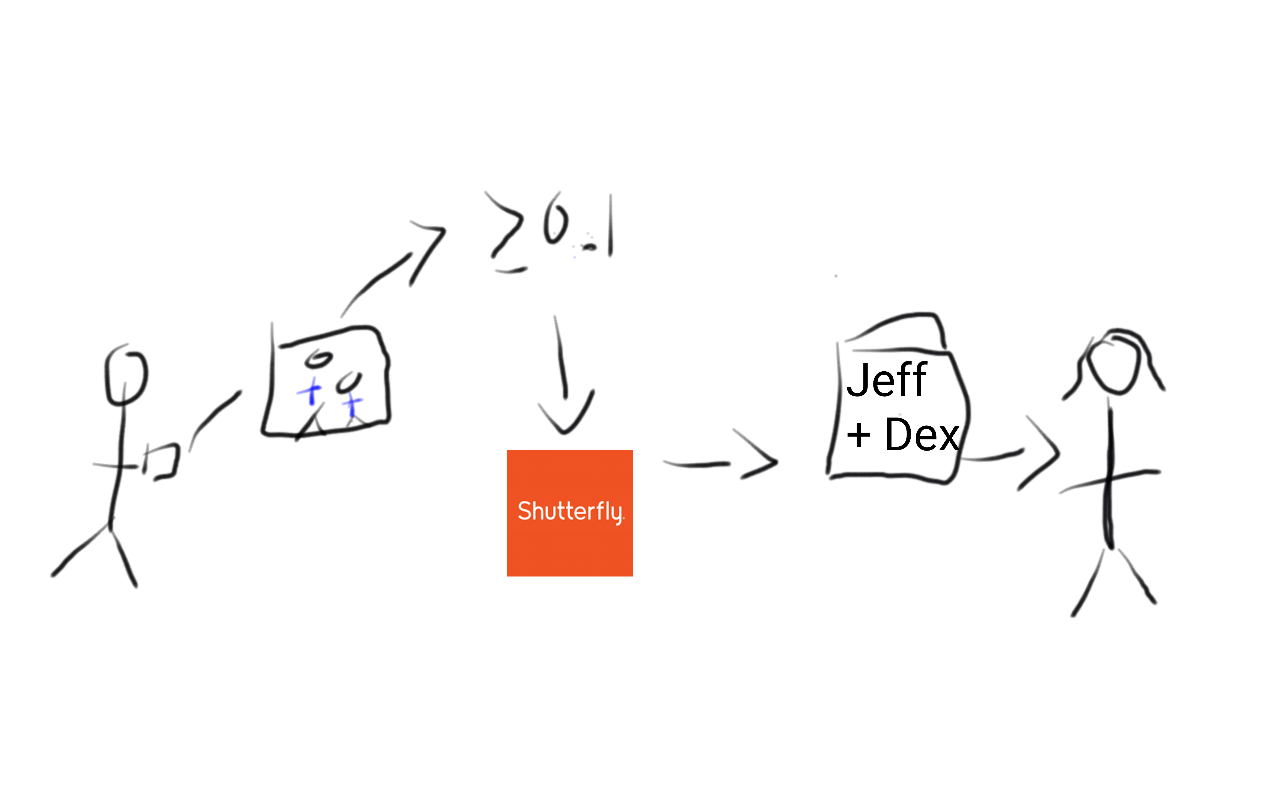
If the algorithm was good, then from the perspective of the author the
website would look “intelligent”. I just uploaded pictures and it
created an album for me with the pictures that I wanted. But the steps
in the process were very simple and understandable behind the scenes.
References
Leek, Jeffrey. n.d. “The Elements of Data Analytic Style.”
{https://leanpub.com/datastyle}.
Raina, Rajat, Alexis Battle, Honglak Lee, Benjamin Packer, and Andrew Y
Ng. 2007. “Self-Taught Learning: Transfer Learning from Unlabeled Data.”
In Proceedings of the 24th International Conference on Machine
Learning, 759–66. ICML ’07. New York, NY, USA: ACM.
Wikipedia contributors. 2016. “Supervised Learning.”
https://en.wikipedia.org/w/index.php?title=Supervised_learning&oldid=752493505.
———. 2017a. “Unsupervised Learning.”
https://en.wikipedia.org/w/index.php?title=Unsupervised_learning&oldid=760556815.
———. 2017b. “Feature Engineering.”
https://en.wikipedia.org/w/index.php?title=Feature_engineering&oldid=760758719.
19 Jan 2017
Editor’s note: This is the first chapter of a book I’m working on called Demystifying Artificial Intelligence. The goal of the book is to demystify what modern AI is and does for a general audience. So something to smooth the transition between AI fiction and highly mathematical descriptions of deep learning. I’m developing the book over time - so if you buy the book on Leanpub know that there is only one chaper in there so far, but I’ll be adding more over the next few weeks and you get free updates. The cover of the book was inspired by this amazing tweet by Twitter user @notajf. Feedback is welcome and encouraged!
What is artificial intelligence?
“If it looks like a duck and quacks like a duck but it needs
batteries, you probably have the wrong abstraction” Derick
Bailey
This book is about artificial intelligence. The term “artificial
intelligence” or “AI” has a long and convoluted history (Cohen and
Feigenbaum 2014). It has been used by philosophers, statisticians,
machine learning experts, mathematicians, and the general public. This
historical context means that when people say artificial intelligence
the term is loaded with one of many potential different meanings.
Humanoid robots
Before we can demystify artificial intelligence it is helpful to have
some context for what the word means. When asked about artificial
intelligence, most people’s imagination leaps immediately to images of
robots that can act like and interact with humans. Near-human robots
have long been a source of fascination by humans have appeared in
cartoons like the Jetsons and science fiction like Star Wars. More
recently, subtler forms of near-human robots with artificial
intelligence have played roles in movies like Her and Ex machina.

The type of artificial intelligence that can think and act like a human
is something that experts call artificial general intelligence
(Wikipedia contributors 2017a).
is the intelligence of a machine that could successfully perform any
intellectual task that a human being can
There is an understandable fascination and fear associated with robots,
created by humans, but evolving and thinking independently. While this
is a major area of ressearch (Laird, Newell, and Rosenbloom 1987) and of
course the center of most people’s attention when it comes to AI, there
is no near term possibility of this type of intelligence (Urban, n.d.).
There are a number of barriers to human-mimicking AI from difficulty
with robotics (Couden 2015) to needed speedups in computational power
(Langford, n.d.).
One of the key barriers is that most current forms of the computer
models behind AI are trained to do one thing really well, but can not be
applied beyond that narrow task. There are extremely effective
artificial intelligence applications for translating between languages
(Wu et al. 2016), for recognizing faces in images (Taigman et al. 2014),
and even for driving cars (Santana and Hotz 2016).
But none of these technologies are generalizable across the range of
tasks that most adult humans can accomplish. For example, the AI
application for recognizing faces in images can not be directly applied
to drive cars and the translation application couldn’t recognize a
single image. While some of the internal technology used in the
applications is the same, the final version of the applications can’t be
transferred. This means that when we talk about artificial intelligence
we are not talking about a general purpose humanoid replacement.
Currently we are talking about technologies that can typically
accomplish one or two specific tasks that a human could accomplish.
Cognitive tasks
While modern AI applications couldn’t do everything that an adult could
do (Baciu and Baciu 2016), they can perform individual tasks nearly as
well as a human. There is a second commonly used definition of
artificial intelligence that is considerably more narrow (Wikipedia
contributors 2017b)
… the term “artificial intelligence” is applied when a machine
mimics “cognitive” functions that humans associate with other human
minds, such as “learning” and “problem solving”.
This definition encompasses applications like machine translation and
facial recognition. They are “cognitive” functions that are generally
usually only performed by humans. A difficulty with this definition is
that it is relative. People refer to machines that can do tasks that we
thought humans could only do as artificial intelligence. But over time,
as we become used to machines performing a particular task it is no
longer surprising and we stop calling it artificial intelligence. John
McCarthy, one of the leading early figures in artificial intelligence
said (Vardi 2012):
As soon as it works, no one calls it AI anymore…
As an example, when you send a letter in the mail, there is a machine
that scans the writing on the letter. A computer then “reads” the
characters on the front of the letter. The computer reads the characters
in several steps - the color of each pixel in the picture of the letter
is stored in a data set on the computer. Then the computer uses an
algorithm that has been built using thousands or millions of other
letters to take the pixel data and turn it into predictions of the
characters in the image. Then the characters are identified as
addresses, names, zipcodes, and other relevant pieces of information.
Those are then stored in the computer as text which can be used for
sorting the mail.
This task used to be considered “artificial intelligence” (Pavlidis,
n.d.). It was surprising that a computer could perform the tasks of
recognizing characters and addresses just based on a picture of the
letter. This task is now called “optical character recognition”
(Wikipedia contributors 2016). Many tutorials on the algorithms behind
machine learning begin with this relatively simple task (Google
Tensorflow Team, n.d.). Optical character recognition is now used in a
wide range of applications including in Google’s effort to digitize
millions of books (Darnton 2009).
Since this type of algorithm has become so common it is no longer called
“artificial intelligence”. This transition happened becasue we no longer
think it is surprising that computers can do this task - so it is no
longer considered intelligent. This process has played out with a number
of other technologies. Initially it is thought that only a human can do
a particular cognitive task. As computers become increasingly proficient
at that task they are called artificially intelligent. Finally, when
that task is performed almost exclusively by computers it is no longer
considered “intelligent” and the boundary moves.
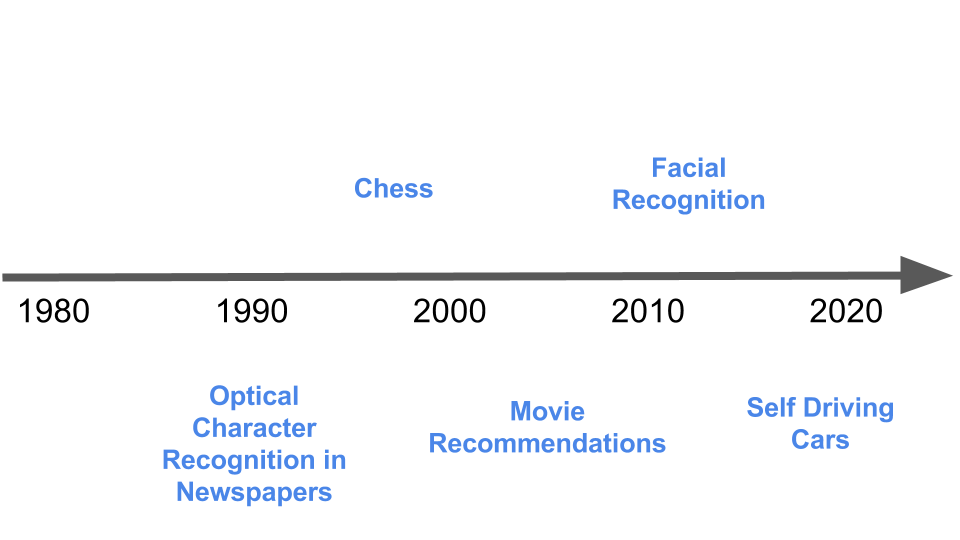
Over the last two decades tasks from optical character recognition, to
facial recognition in images, to playing chess have started as
artificially intelligent applications. At the time of this writing there
are a number of technologies that are currently on the boundary between
doable only by a human and doable by a computer. These are the tasks
that are considered AI when you read about the term in the media.
Examples of tasks that are currently considered “artificial
intelligence” include:
- Computers that can drive cars
- Computers that can identify human faces from pictures
- Computers that can translate text from one language to another
- Computers that can label pictures with text descriptions
Just as it used to be with optical character recognition, self-driving
cars and facial recognition are tasks that still surprise us when
performed by a computer. So we still call them artificially intelligent.
Eventually, many or most of these tasks will be performed nearly
exclusively by computers and we will no longer think of them as
components of computer “intelligence”. To go a little further we can
think about any task that is repetitive and performed by humans. For
example, picking out music that you like or helping someone buy
something at a store. An AI can eventually be built to do those tasks
provided that: (a) there is a way of measuring and storing information
about the tasks and (b) there is technology in place to perform the task
if given a set of computer instructions.
The more narrow definition of AI is used colloquially in the news to
refer to new applications of computers to perform tasks previously
thought impossible. It is important to know both the definition of AI
used by the general public and the more narrow and relative definition
used to describe modern applications of AI by companies like Google and
Facebook. But neither of these definitions is satisfactory to help
demystify the current state of artificial intelligence applications.
A three part definition
The first definition describes a technology that we are not currently
faced with - fully functional general purpose artificial intelligence.
The second definition suffers from the fact that it is relative to the
expectations of people discussing applications. For this book, we need a
definition that is concrete, specific, and doesn’t change with societal
expectations.
We will consider specific examples of human-like tasks that computers
can perform. So we will use the definition that artificial intelligence
requires the following components:
- The data set : A of data examples that can be used to train a
statistical or machine learning model to make predictions.
- The algorithm : An algorithm that can be trained based on the data
examples to take a new example and execute a human-like task.
- The interface : An interface for the trained algorithm to receive
a data input and execute the human like task in the real world.
This definition encompases optical character recognition and all the
more modern examples like self driving cars. It is also intentionally
broad, covering even examples where the data set is not large or the
algorithm is not complicated. We will use our definition to break down
modern artificial intelligence applications into their constituitive
parts and make it clear how the computer represents knowledge learned
from data examples and then applies that knowledge.
As one example, consider Amazon Echo and Alexa - an application
currently considered to be artificially intelligent (Nuñez, n.d.). This
combination meets our definition of artificially intelligent since each
of the components is in place.
- The data set : The large set of data examples consist of all the
recordings that Amazon has collected of people talking to their
Amazon devices.
- The machine learning algorithm : The Alexa voice service (Alexa
Developers 2016) is a machine learning algorithm trained using the
previous recordings of people talking to Amazon devices.
- The interface : The interface is the Amazon Echo (Amazon Inc 2016)
a speaker that can record humans talking to it and respond with
information or music.

When we break down artificial intelligence into these steps it makes it
clearer why there has been such a sudden explosion of interest in
artificial intelligence over the last several years.
First, the cost of data storage and collection has gone down steadily
(Irizarry, n.d.) but dramatically (Quigley, n.d.) over the last several
years. As the costs have come down, it is increasingly feasible for
companies, governments, and even individuals to store large collections
of data (Component 1 - The Data). To take advantage of these huge
collections of data requires incredibly flexible statistical or machine
learning algorithms that can capture most of the patterns in the data
and re-use them for prediction. The most common type of algorithms used
in modern artificial intelligence are something called “deep neural
networks”. These algorithms are so flexible they capture nearly all of
the important structure in the data. They can only be trained well if
huge data sets exist and computers are fast enough. Continual increases
in computing speed and power over the last several decades now make it
possible to apply these models to use collections of data (Component 2 -
The Algorithm).
Finally, the most underappreciated component of the AI revolution does
not have to do with data or machine learning. Rather it is the
development of new interfaces that allow people to interact directly
with machine learning models. For a number of years now, if you were an
expert with statistical and machine learning software it has been
possible to build highly accurate predictive models. But if you were a
person without technical training it was not possible to directly
interact with algorithms.
Or as statistical experts Diego Kuonen and Rafael Irizarry have put it:
The big in big data refers to importance, not size
The explosion of interfaces for regular, non-technical people to
interact with machine learning is an underappreciated driver of the AI
revolution of the last several years. Artificial intelligence can now
power labeling friends on Facebook, parsing your speech to your personal
assistant Siri or Google Assistant, or providing you with directions in
your car, or when you talk to your Echo. More recently sensors and
devices make it possible for the instructions created by a computer to
steer and drive a car.
These interfaces now make it possible for hundreds of millions of people
to directly interact with machine learning algorithms. These algorithms
can range from exceedingly simple to mind bendingly complex. But the
common result is that the interface allows the computer to perform a
human-like action and makes it look like artificial intelligence to the
person on the other side. This interface explosion only promises to
accelerate as we are building sensors for both data input and behavior
output in objects from phones to refrigerators to cars (Component 3 -
The interface).
This definition of artificial intelligence in three components will
allow us to demystify artificial intelligence applications from self
driving cars to facial recognition. Our goal is to provide a high-level
interface to the current conception of AI and how it can be applied to
problems in real life. It will include discussion and references to the
sophisticated models and data collection methods used by Facebook,
Tesla, and other companies. However, the book does not assume a
mathematical or computer science background and will attempt to explain
these ideas in plain language. Of course, this means that some details
will be glossed over, so we will attempt to point the interested reader
toward more detailed resources throughout the book.
References
Alexa Developers. 2016. “Alexa Voice Service.”
https://developer.amazon.com/alexa-voice-service.
Amazon Inc. 2016. “Amazon Echo.”
https://www.amazon.com/Amazon-Echo-Bluetooth-Speaker-with-WiFi-Alexa/dp/B00X4WHP5E.
Baciu, Assaf, and Assaf Baciu. 2016. “Artificial Intelligence Is More
Artificial Than Intelligent.” Wired, 7~dec.
Cohen, Paul R, and Edward A Feigenbaum. 2014. The Handbook of
Artificial Intelligence. Vol. 3. Butterworth-Heinemann.
https://goo.gl/wg5rMk.
Couden, Craig. 2015. “Why It’s so Hard to Make Humanoid Robots | Make:”
http://makezine.com/2015/06/15/hard-make-humanoid-robots/.
Darnton, Robert. 2009. Google & the Future of Books. na.
Google Tensorflow Team. n.d. “MNIST for ML Beginners | TensorFlow.”
https://www.tensorflow.org/tutorials/mnist/beginners/.
Irizarry, Rafael. n.d. “The Big in Big Data Relates to Importance Not
Size · Simply Statistics.”
http://simplystatistics.org/2014/05/28/the-big-in-big-data-relates-to-importance-not-size/.
Laird, John E, Allen Newell, and Paul S Rosenbloom. 1987. “Soar: An
Architecture for General Intelligence.” Artificial Intelligence 33
(1). Elsevier: 1–64.
Langford, John. n.d. “AlphaGo Is Not the Solution to AI « Machine
Learning (Theory).” http://hunch.net/?p=3692542.
Nuñez, Michael. n.d. “Amazon Echo Is the First Artificial Intelligence
You’ll Want at Home.”
http://www.popsci.com/amazon-echo-first-artificial-intelligence-youll-want-home.
Pavlidis, Theo. n.d. “Computers Versus Humans - 2002 Lecture.”
http://www.theopavlidis.com/comphumans/comphuman.htm.
Quigley, Robert. n.d. “The Cost of a Gigabyte over the Years.”
http://www.themarysue.com/gigabyte-cost-over-years/.
Santana, Eder, and George Hotz. 2016. “Learning a Driving Simulator,”
3~aug.
Taigman, Y, M Yang, M Ranzato, and L Wolf. 2014. “DeepFace: Closing the
Gap to Human-Level Performance in Face Verification.” In 2014 IEEE
Conference on Computer Vision and Pattern Recognition, 1701–8.
Urban, Tim. n.d. “The AI Revolution: How Far Away Are Our Robot
Overlords?”
http://gizmodo.com/the-ai-revolution-how-far-away-are-our-robot-overlords-1684199433.
Vardi, Moshe Y. 2012. “Artificial Intelligence: Past and Future.”
Commun. ACM 55 (1). New York, NY, USA: ACM: 5–5.
Wikipedia contributors. 2016. “Optical Character Recognition.”
https://en.wikipedia.org/w/index.php?title=Optical_character_recognition&oldid=757150540.
———. 2017a. “Artificial General Intelligence.”
https://en.wikipedia.org/w/index.php?title=Artificial_general_intelligence&oldid=758867755.
———. 2017b. “Artificial Intelligence.”
https://en.wikipedia.org/w/index.php?title=Artificial_intelligence&oldid=759177704.
Wu, Yonghui, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi,
Wolfgang Macherey, Maxim Krikun, et al. 2016. “Google’s Neural Machine
Translation System: Bridging the Gap Between Human and Machine
Translation,” 26~sep.
18 Jan 2017
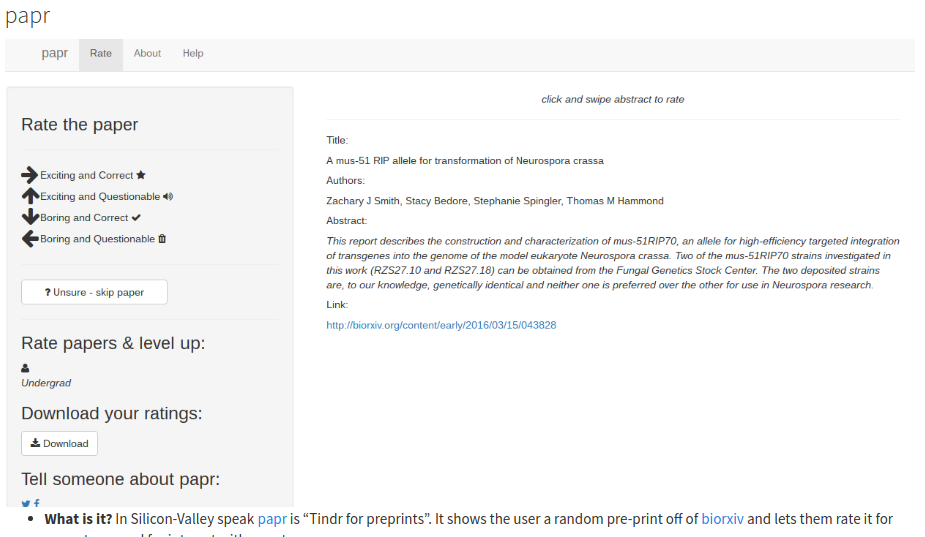
Last fall we ran the first iteration of a class at the Johns Hopkins Data Science Lab where we teach students to build data web-apps using Shiny, R, GoogleSheets and a number of other technologies. Our goals were to teach students to build data products, to reduce friction for students who want to build things with data, and to help people solve important data problems with web and SMS apps.
We are going to be running a second iteration of our program from March-June this year. We are looking for awesome projects for students to build that solve real world problems. We are particularly interested in projects that could have a positive impact on health but are open to any cool idea. We generally build apps that are useful for:
- Data donation - if you have a group of people you would like to donate data to your project.
- Data collection - if you would like to build an app for collecting data from people.
- Data visualziation - if you have a data set and would like to have a web app for interacting with the data
- Data interaction - if you have a statistical or machine learning model and you would like a web interface for it.
But we are interested in any consumer-facing data product that you might be interested in having built. We want you to submit your wildest, most interesting ideas and we’ll see if we can get them built for you.
We are hoping to solicit a large number of projects and then build as many as possible. The best part is that we will build the prototype for you for free! If you have an idea of something you’d like built please submit it to this Google form.
Students in the class will select projects they are interested in during early March. We will let you know if your idea was selected for the program by mid-March. If you aren’t selected you will have the opportunity to roll your submission over to our next round of prototyping.
I’ll be writing a separate post targeted at students, but if you are interested in being a data app prototyper, sign up here.
 Follow us on twitter
Follow us on twitter